
PythonでAI開発をやりたい!
AI開発ってどうやってするの
今回はAI開発の一つである画像認識AIをPythonで実装してみたいと思います。画像認識はAI開発の中での一番技術が発展しており、世の中でも活用されているところがたくさんあります。
今回は簡単なデータセットを用いた画像の分類をAIにさせてみるという問題に取り組みます。
Pythonで実際にどのようにAI開発がされているかわからない方の助けになると嬉しいです。また、初学者でも簡単にPythonでAI開発ができるため是非チャレンジしてみてください!


AIとは

学術的にAIは多岐にわたるため、学者によって捉え方が異なります。ここではひとまず、コンピュータが画像・音声・文字・数値データを認知・判断・行動する技術ということにします。
AIという言葉を耳にするとき同じように似たような意味を指す言葉として機械学習やディープラーニングという言葉を聞いたことはないでしょうか。
こちらの2つの言葉の違いはいったい何でしょうか?
AIを実現するための技術が機械学習と言えます。そして機械学習という技術の中にディープラーニングと呼ばれる手法があります。(AI > 機械学習 > ディープラーニング という関係性です)
図で見るとわかりやすいと思います。基礎知識として言葉の違いを理解しておきましょう。


AI開発ライブラリ

PythonでAI開発を行うためのライブラリを簡単に紹介します。機械学習やディープラーニングを行うためには必須と言えるものになります!
余談ですが、ライブラリの豊富さがPythonの人気ともいえるところです。
scikit-learn
データの前処理や機械学習を行う際に用いるライブラリです。
前処理の標準化処理や機械学習を3行ほどのコードだけで実行できてしまうほどの有能なライブラリになります。
AI開発だけではなくデータ分析などにも活用されている必須ライブラリの一つと言えます!
TensorFlowとKeras
こちらはGoogleが開発しているニューラルネットワークのオープンソースライブラリです。
TensorFlowではKerasなどの直感的なAPIを使用すると、TensorFlowや機械学習の知識がなくても簡単に始めることができます。
KerasはPythonで書かれたTensorFlow上で実行化可能なニューラルネットワークライブラリです。
- 初心者に使いやすいインターフェース
- CPUとGPU上でシームレスに動作する
TensorFlowは様々な業界の多くの企業が導入しております。医療業界からネット業界まで幅広い企業が活用しており、我々の生活の身近なところで活用されています。
- aribnb
- CocaCola
- intel
- Spotify
Pytorch
こちらはFacebookが開発しているニューラルネットワークのオープンソースライブラリです。
こちらは先に紹介したTensorFlow、Kerasと同じくらい人気があるライブラリになっております。世の中の大多数がTensorFlow、Keras、Pytorchのどれかを使ってAI開発をされています。
少し前までは、日本で開発されたニューラルネットワークライブラリのChainerが人気がありました。
こちらは、Pytorchはコードの書き方が似ております。しかし、Chainerの開発元であるPreferred Networkは2019年にメジャーアップデートを終了することを発表しました。また、Preferred Networkの研究開発基盤をChainerからPytorchへ移行するようです。
- 直感的にコードが書ける
- Numpyベースの演算の代わりのGPUを用いた高度な演算
- 高い柔軟性と実行速度を持つ
画像認識AIの実装

今回はTensorFlow、Kerasを使ったディープラーニングによる画像認識AIを作成してみたいと思います。
Googleが提供しているPytohn学習プラットフォームのGoogle Colaboratoryを使用することでPython環境やGPU計算をブラウザ上で無料でできるためおすすめです!

ライブラリの読み込み
Google Colaboratoryのランタイムの設定をGPUに設定します。この後のモデルの学習を行う際にGPUに設定しておくと計算が早くなります。
次に、下記のライブラリを読み込みます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Model
from tensorflow.keras import layers
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnistGoogle ColaboratoryのGPUが接続できているか確認をしてみます。下記のコマンドで確認します。
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 4726345767496427866
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 7250706432
locality {
bus_id: 1
links {
}
}
incarnation: 6972724881437462404
physical_device_desc: "device: 0, name: Tesla P4, pci bus id: 0000:00:04.0, compute capability: 6.1"/device:GPU0となっているのでGPUが繋がっていることが確認できます
データセットの読み込み
今回はデータセットのとしてMNISTの手書き文字を読み込みます。
train, test = mnist.load_data()データセットの中身を確認してみます。
train[0].shape, train[1].shape
>>>((60000, 28, 28), (60000,))
test[0].shape, test[1].shape
>>>((10000, 28, 28), (10000,))
type(train), type(train[0])
>>>(tuple, numpy.ndarray)train, testにはそれぞれ60000個,10000個のデータがあります。
こちらは28×28の画像サイズで0~9までの手書き文字のデータセットになります。それぞれの手書き文字データにラベルが付加されております。
- train[0] 学習用の手書き文字データ
- train[1] 学習用ラベル
- test[0] 検証用の手書き文字データ
- test[1] 検証用ラベル
いくつか可視化してみます。
row = 2
col = 5
cnt = 0
fig, ax = plt.subplots(row, col, figsize=(15,5))
plt.gray()
for i in range(row):
for j in range(col):
ax[i, j].imshow(train[0][cnt])
cnt += 1
plt.show()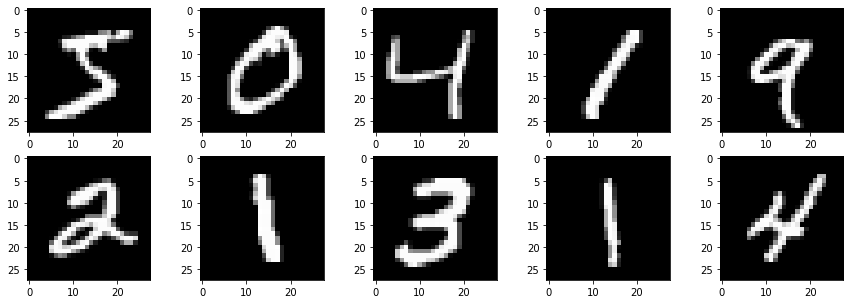
手書きで書かれた数字が確認できます。
データセットの前処理
ディープラーニングに入力するためにデータを前処理する必要があります。
今回のデータは白黒画像のためにチャンネル数は1になります。(カラー画像の場合はRGBでチャンネル数は3になります。)
また、画像データのピクセル値は0~255の値までしか取らないため、255で割ることで0~1の範囲に値を正規化します。
# reshape (n, width, height) => (n, width, height, channel)
x_train = train[0].reshape(60000, 28, 28, 1)/255
x_test = test[0].reshape(10000, 28, 28, 1)/255- 入力のshapeは(n, width, height, channe)
- 画像データは255で正規化
ラベルデータも前処理を行います。こちらはOne-hot vectorと呼ばれる処理を行います。
# One hot vector
t_train = to_categorical(train[1])
t_test = to_categorical(test[1])x_train.shape
>>>(60000, 28, 28, 1)
t_train.shape
>>>(60000, 10)モデル構築
簡単なディープラーニングモデルを作成します。
tf.keras.backend.clear_session()
inputs = layers.Input(shape=x_train.shape[1:])
x = layers.Conv2D(filters=3, kernel_size=(3, 3), padding='same', activation='relu')(inputs)
x = layers.MaxPool2D(pool_size=(2, 2))(x)
x = layers.Flatten()(x)
x = layers.Dense(units=128, activation='relu')(x)
outpus = layers.Dense(units=10, activation='softmax')(x)
model = Model(inputs, outpus)
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=optimizer,
loss='categorical_crossentropy',
metrics=['accuracy'])_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 28, 28, 3) 30
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 3) 0
_________________________________________________________________
flatten (Flatten) (None, 588) 0
_________________________________________________________________
dense (Dense) (None, 128) 75392
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 76,712
Trainable params: 76,712
Non-trainable params: 0
_________________________________________________________________学習
batch_size =2048
epochs =30
history = model.fit(x_train, t_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, t_test))Epoch 1/30
30/30 [==============================] - 1s 17ms/step - loss: 0.6221 - accuracy: 0.8375 - val_loss: 0.2406 - val_accuracy: 0.9297
Epoch 2/30
30/30 [==============================] - 0s 12ms/step - loss: 0.1960 - accuracy: 0.9422 - val_loss: 0.1488 - val_accuracy: 0.9554
Epoch 3/30
30/30 [==============================] - 0s 13ms/step - loss: 0.1341 - accuracy: 0.9598 - val_loss: 0.1150 - val_accuracy: 0.9643
Epoch 4/30
30/30 [==============================] - 0s 12ms/step - loss: 0.1044 - accuracy: 0.9693 - val_loss: 0.0972 - val_accuracy: 0.9695
Epoch 5/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0862 - accuracy: 0.9740 - val_loss: 0.0924 - val_accuracy: 0.9709
Epoch 6/30
30/30 [==============================] - 0s 11ms/step - loss: 0.0747 - accuracy: 0.9776 - val_loss: 0.0822 - val_accuracy: 0.9732
Epoch 7/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0659 - accuracy: 0.9798 - val_loss: 0.0855 - val_accuracy: 0.9733
Epoch 8/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0612 - accuracy: 0.9814 - val_loss: 0.0730 - val_accuracy: 0.9766
Epoch 9/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0518 - accuracy: 0.9841 - val_loss: 0.0695 - val_accuracy: 0.9780
Epoch 10/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0448 - accuracy: 0.9867 - val_loss: 0.0701 - val_accuracy: 0.9766
Epoch 11/30
30/30 [==============================] - 0s 11ms/step - loss: 0.0417 - accuracy: 0.9872 - val_loss: 0.0624 - val_accuracy: 0.9791
Epoch 12/30
30/30 [==============================] - 0s 11ms/step - loss: 0.0352 - accuracy: 0.9892 - val_loss: 0.0674 - val_accuracy: 0.9766
Epoch 13/30
30/30 [==============================] - 0s 11ms/step - loss: 0.0316 - accuracy: 0.9903 - val_loss: 0.0746 - val_accuracy: 0.9770
Epoch 14/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0282 - accuracy: 0.9912 - val_loss: 0.0749 - val_accuracy: 0.9776
Epoch 15/30
30/30 [==============================] - 0s 13ms/step - loss: 0.0234 - accuracy: 0.9933 - val_loss: 0.0676 - val_accuracy: 0.9803
Epoch 16/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0203 - accuracy: 0.9941 - val_loss: 0.0678 - val_accuracy: 0.9799
Epoch 17/30
30/30 [==============================] - 0s 11ms/step - loss: 0.0176 - accuracy: 0.9948 - val_loss: 0.0684 - val_accuracy: 0.9794
Epoch 18/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0151 - accuracy: 0.9957 - val_loss: 0.0679 - val_accuracy: 0.9801
Epoch 19/30
30/30 [==============================] - 0s 11ms/step - loss: 0.0127 - accuracy: 0.9965 - val_loss: 0.0655 - val_accuracy: 0.9817
Epoch 20/30
30/30 [==============================] - 0s 13ms/step - loss: 0.0106 - accuracy: 0.9975 - val_loss: 0.0683 - val_accuracy: 0.9795
Epoch 21/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0104 - accuracy: 0.9973 - val_loss: 0.0678 - val_accuracy: 0.9806
Epoch 22/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0074 - accuracy: 0.9984 - val_loss: 0.0706 - val_accuracy: 0.9816
Epoch 23/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0057 - accuracy: 0.9991 - val_loss: 0.0718 - val_accuracy: 0.9800
Epoch 24/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0052 - accuracy: 0.9991 - val_loss: 0.0725 - val_accuracy: 0.9801
Epoch 25/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0043 - accuracy: 0.9994 - val_loss: 0.0756 - val_accuracy: 0.9814
Epoch 26/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0037 - accuracy: 0.9995 - val_loss: 0.0754 - val_accuracy: 0.9816
Epoch 27/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0028 - accuracy: 0.9996 - val_loss: 0.0799 - val_accuracy: 0.9817
Epoch 28/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0021 - accuracy: 0.9998 - val_loss: 0.0782 - val_accuracy: 0.9807
Epoch 29/30
30/30 [==============================] - 0s 12ms/step - loss: 0.0016 - accuracy: 0.9999 - val_loss: 0.0777 - val_accuracy: 0.9823
Epoch 30/30
30/30 [==============================] - 0s 11ms/step - loss: 0.0014 - accuracy: 0.9999 - val_loss: 0.0800 - val_accuracy: 0.9818results = pd.DataFrame(history.history)
results[['loss', 'val_loss']].plot()
results[['accuracy', 'val_accuracy']].plot()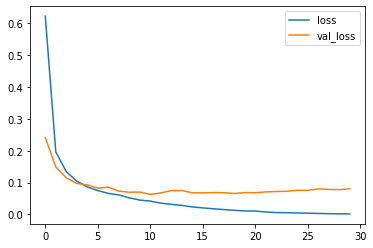
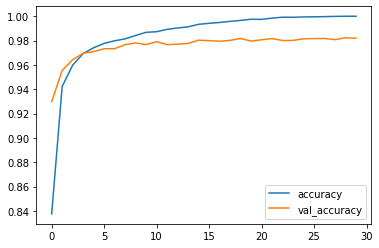
学習が進むにつれて誤差は低下し、精度は向上しているので、学習がしっかりできているようです。
推論
それでは先ほど作成したモデルに文字認識をさせてみます。
未知のデータに対してAIが判別結果を出すことを推論または予測と言ったりします。
検証用のデータを学習モデルに入力してみましょう。
まずは入力する画像を確認します。
x = test[0][0]
t = test[1][0]
plt.imshow(x)
plt.show()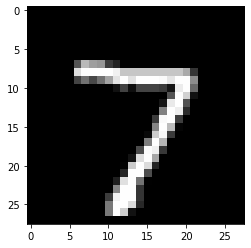
こちらの7の画像を画像認識AIに入力できる形に変換します。
x = np.array([x_test[0]])
x.shape
>(1, 28, 28, 1)画像認識AIに推論させてみます。
推論はとても簡単でpredictとするだけになります。
y = model.predict(x)推論の結果は0~9の10クラス分類になるため、それぞれのクラスである確率が出力されます。
y
>>>array([[1.9422271e-14, 6.0360928e-16, 1.9026161e-11, 6.4874790e-08,
1.3578780e-18, 1.6909820e-12, 5.0483538e-29, 9.9997830e-01,
1.7392731e-09, 2.1594884e-05]], dtype=float32)一番確率の高い分類クラスを推論結果として確認します
np.argmax(y)
>>>7画像認識AIはしっかりと画像を認識して7と言う結果を出力できることがわかります。
まとめ

今回は簡単な画像認識AIをPythonを使って実装してみました。ライブラリを使うことで画像認識AIを数行で簡単に作成することができます。
スマートフォンの顔認証システムや自動運転技術もこちらを応用することで開発されています。
今回はTensorFlow、Kerasを使ったコードでしたが、Pytorchでは書き方が異なります。しかし、重要なところはPythonを使って何をやりたいかです。あくまでもライブラリは手段にしか過ぎないため、その時々に使い分けることもあると思います。


コメント