
Webスクレイピングを学びたい
PythonでWeb操作を自動化する方法がわからない
今回は私が作成したスクレイピング練習用のWebサイトを使ってPythonでWebスクレイピングの方法を紹介します。
- Webブラウザ操作を自動化
- Webブラウザ上のデータ取得
Webブラウザ操作の自動化はWeb画面の中で人が行うボタンのクリックや画面のスクロール、テキストの入力をする方法を紹介します。
Webブラウザ上のデータ取得はWebブラウザにあるテキストデータや画像データを取得する方法を紹介します。
盛りだくさんの内容となりますが、最後まで是非実践してみましょう。今回の内容はHTMLの基礎的な知識があると理解がしやすいです。
WebをPythonで操作するための第一歩だと思います。初学者でも簡単に実践できるのでチャレンジしてみてください!


Web操作を自動化

PythonでWeb操作を自動化する方法を紹介していきます。
今回は私が作成したスクレイピング練習用ページを使ってWebサイトなどでよく見かけるサインインページをPythonを使って自動化するというタスクに取り組んでみましょう。
手順を下記にまとめました。とても簡単ですので1つずつ確実に理解していきましょう。
- 必要なライブラリのインストール
- ブラウザの起動
- Webサイトにアクセス
- Webサイトにログイン
手順ごとに詳しくみていきましょう。
![]() 必要なライブラリのインストール
必要なライブラリのインストール
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import KeysSeleniumというライブラリを使ってPythonでWeb操作を行います。
PythonでWebブラウザの操作を自動化するためのライブラリ
![]() ブラウザの起動
ブラウザの起動
browser = webdriver.Chrome(ChromeDriverManager().install())実行するとChromeブラウザが起動します。
browser.quit() # ブラウザを閉じる![]() Webサイトにアクセス
Webサイトにアクセス
Webサイトにアクセスするにはget()の中にアクセスしたいWebサイトのURLを入れます。
browser.get('https://www.google.com/') # getの引数にURLを入力することでログイン可能先ほど起動したブラウザ画面が指定したリンク先に変わったと思います。
![]() Webサイトにログイン
Webサイトにログイン
それでは、私が作成したWebサイトを使ってログインの自動化を実践してみましょう。
下記URLを入力してブラウザを起動させます。
url = 'https://hitori-sekai.com/scraping/signin.html'
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get(url) # getの引数にURLを入力することでログイン可能====== WebDriver manager ======
Current google-chrome version is 91.0.4472
Get LATEST driver version for 91.0.4472
Get LATEST driver version for 91.0.4472
Trying to download new driver from https://chromedriver.storage.googleapis.com/91.0.4472.101/chromedriver_win32.zip
Driver has been saved in cache [C:\Users\toshi\.wdm\drivers\chromedriver\win32\91.0.4472.101]こちらのWebサイトの「ID」と「Password」の項目を入力し、「sign in ボタン」を押すというログイン作業を自動化させてみます。
Web操作をするときに注意することは
- どの場所に
- どんなアクションを起こしたいか
この2つがわかればプログラムで自動化ができます。
それでは、HTMLの構造を確認するために 右クリック → 検証 で検証ページを開きます。
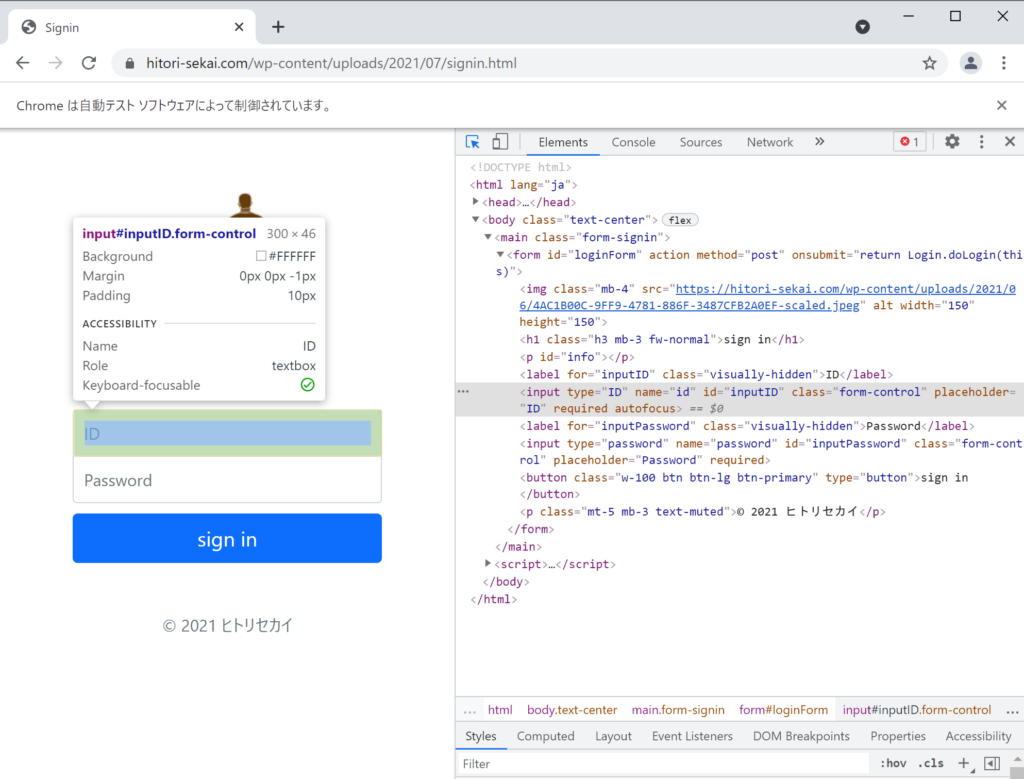
「ID」の入力フォームの構造はinputタグを使っていることがわかります。さらに、idがinputIDとなっているので今回はこちらを使って場所を指定します。
idがわかる場合はfind_element_by_idを使って場所を指定することができます。
elem_id= browser.find_element_by_id('inputID') #場所の取得場所の指定方法は他にもいろいろあります。HTMLの構造を確認するとinputタグやclassも記載されているのでそちらを使ってもできます。
- find_element_by_tag_name:inputタグを使って指定する場合
- find_element_by_class_name:classを使って指定する場合
場所を指定したら次はアクションを行います。今回はIDの部分にテキストを入力するというアクションになります。
こちらのログインするためのIDとPasswordの情報は
- ID: hitori-sekai
- Password: python
になっております。
それでは、先ほど指定した場所にsend_keysを使ってIDを入力します。
elem_id.send_keys('hitori-sekai') #テキスト入力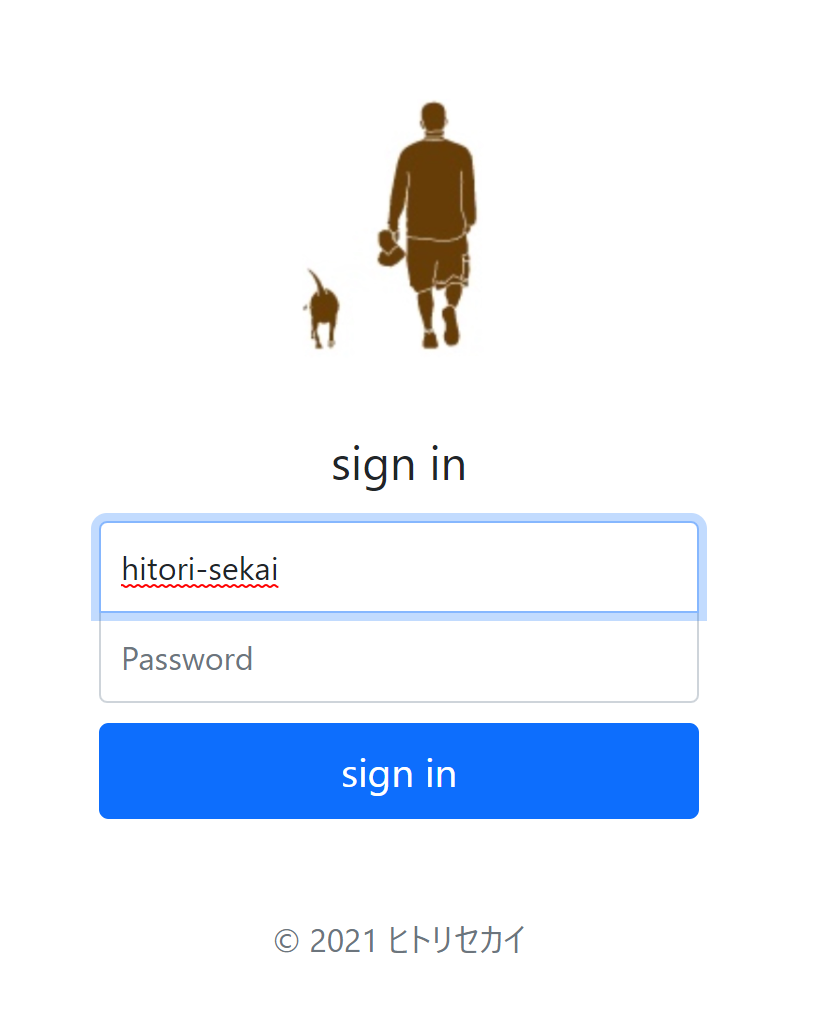
実行するとIDのところに入力されていることが確認できます。
Passwordの入力もIDと同様に場所指定して、入力します。
elem_password= browser.find_element_by_id('inputPassword') #場所の取得
elem_password.send_keys('python') #テキスト入力
最後のアクションはどうでしょうか。ここまでくると気づいた方が多いと思います。
sing inボタンの場所を指定して、クリックするというアクションを行えば良いですね。
elem_button = browser.find_element_by_tag_name('button') #場所の取得
elem_button.click() #クリック
スクレイピング練習ページに遷移できているとログイン完了です。
以降では、こちらのWebページを使ってテキストデータや画像データの取得方法を紹介します。
テキストデータを取得

次はテキストデータを取得する方法を紹介します。
- Tableページへ移動
- 場所の指定、テキストデータの取得
- 取得データの出力
手順ごとに詳しくみていきましょう。
![]() Tableページへ移動
Tableページへ移動
Tableボタンを押して下記のページに移動しましょう。
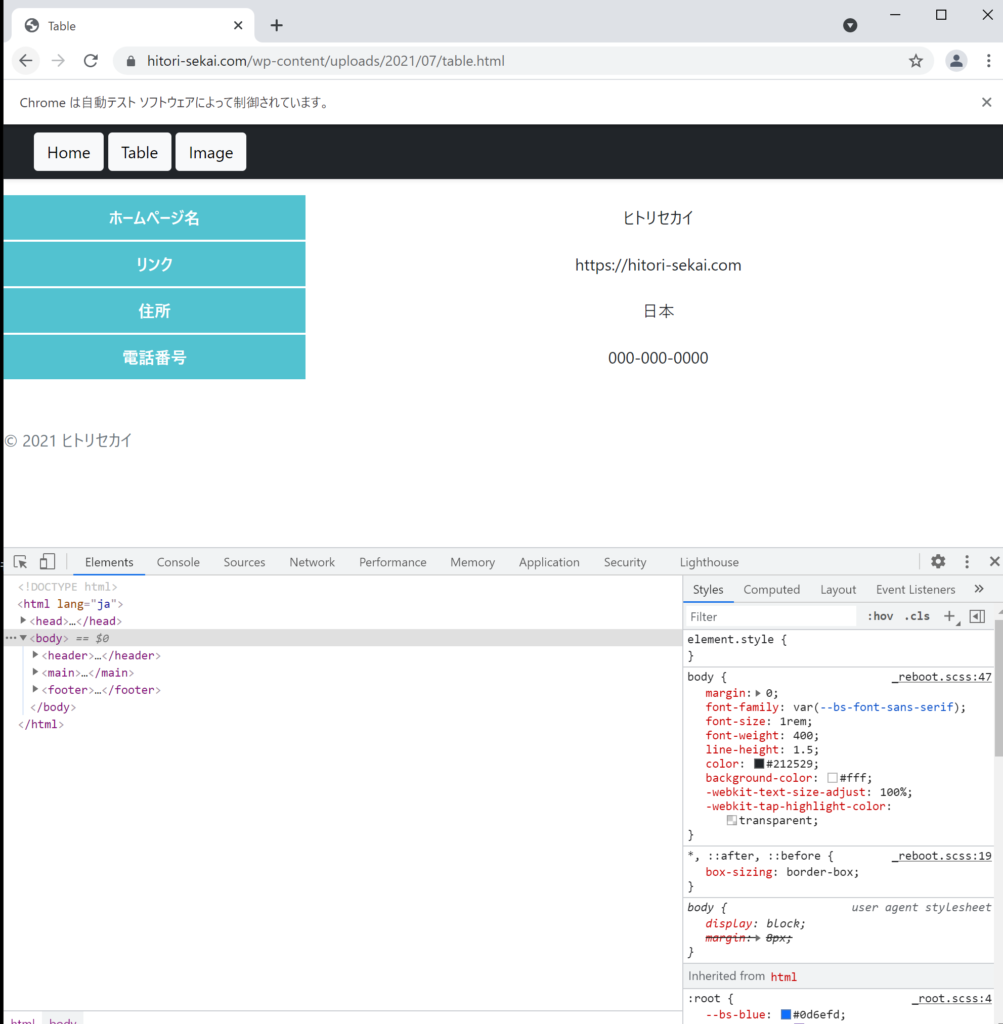
表のテキストデータを取得してファイルにまとめるという作業をPythoneで実践します。
![]() 場所の指定、テキストデータの取得
場所の指定、テキストデータの取得
1つの要素をを取得する方法
先ほどと同じように検証ツールを用いて表のタグを確認します。
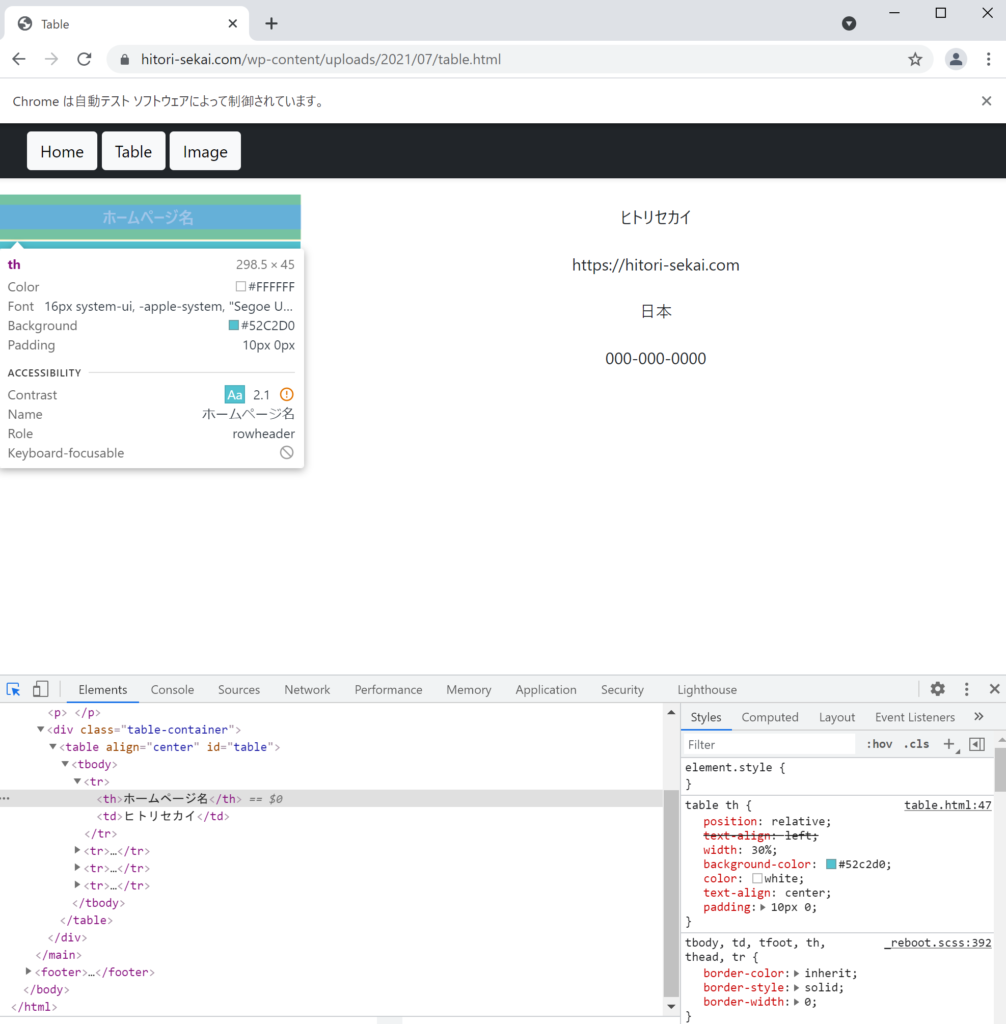
thタグを使っていることがわかります。
それでは、thタグの場所を指定してあげます。
elem_th = browser.find_element_by_tag_name('th')
elem_th[<selenium.webdriver.remote.webelement.WebElement (session="f85bc3da45248b8b0850757e615cb585", element="04a432bc-ad01-4b96-9331-25e6f2f24585")>]指定した要素のテキストデータは.textを使用することで確認できます。
print(elem_th.text)
>>> ホームページ名要素のテキストを取得できていることが確認できます。
複数の要素を取得する方法
Webサイトの中には先ほど取得したthタグの他にもthタグは複数あります。表のthタグを複数取得する方法をみていきましょう。
先程までのelementは最初の1つだけの場所を取得します。複数取得したい場合はelementsを使いましょう。
browser.find_element_by_tag_name('th') #最初の1つだけ
browser.find_elements_by_tag_name('th') #全てそれでは複数のテキストデータの取得を実践します。
elem_ths = browser.find_elements_by_tag_name('th')
elem_ths[<selenium.webdriver.remote.webelement.WebElement (session="f85bc3da45248b8b0850757e615cb585", element="04a432bc-ad01-4b96-9331-25e6f2f24585")>,
<selenium.webdriver.remote.webelement.WebElement (session="f85bc3da45248b8b0850757e615cb585", element="848d79a8-0599-4e8b-b751-9fa36d30ec49")>,
<selenium.webdriver.remote.webelement.WebElement (session="f85bc3da45248b8b0850757e615cb585", element="9d4213b6-148f-4e61-8e3c-36752a7579c2")>,
<selenium.webdriver.remote.webelement.WebElement (session="f85bc3da45248b8b0850757e615cb585", element="76c1005d-ff82-45b9-9329-d31e1e13424a")>]リスト型で4つの場所が取得できていることが確認できます。
for文を使うとそれぞれのテキストデータを取得できます。
th_list = []
for elem_th in elem_ths:
th_list.append(elem_th.text)th_list
>>> ['ホームページ名', 'リンク', '住所', '電話番号']表の左列の要素を全て取得できました。
次は同じように表の右側の列の要素を取得します。右側の列の要素はtdタグを使ってます。
elem_tbs = browser.find_elements_by_tag_name('td')
tb_list = []
for elem_tb in elem_tbs:
tb_list.append(elem_tb.text)tb_list
>>> ['ヒトリセカイ', 'https://hitori-sekai.com', '日本', '000-000-0000']簡単に取得できました。
![]() 取得データの出力
取得データの出力
それでは最後に取得したデータをまとめてcsvファイルに出力してみます。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.array([th_list, tb_list]).T, columns=['title', 'data'])
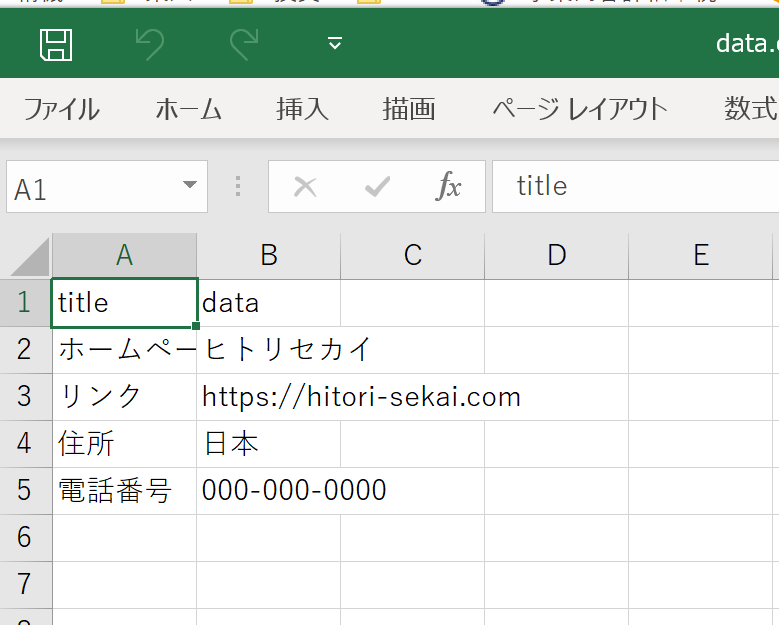
df.head()| index | title | data |
|---|---|---|
| 0 | ホームページ名 | ヒトリセカイ |
| 1 | リンク | https://hitori-sekai.com |
| 2 | 住所 | 日本 |
| 3 | 電話番号 | 000-000-0000 |
表から取得したテキストデータをDataFrameにまとめ、csvファイルに出力します。
df.to_csv('data.csv', encoding='cp932', index=False)出力したcsvファイルを確認してみます。
画像データを取得

最後に画像データを取得する方法を紹介します。
今回はBeautihulsoup4という別のライブラリを使って画像データの取得を行う方法を紹介します。先ほどのテキストデータのもBeautihulsoup4を使って行うこともできます。
Beautihulsoup4はHTMLから必要な情報を抽出するライブラリです。HTMLの中身を解析して構造ツリーにして目的のコンテンツを取得できます。
- Imageページへ移動
- ライブラリのインストール
- 場所の指定、画像データの取得
- 取得データの出力
手順ごとに詳しくみていきましょう。
![]() Imageページへ移動
Imageページへ移動
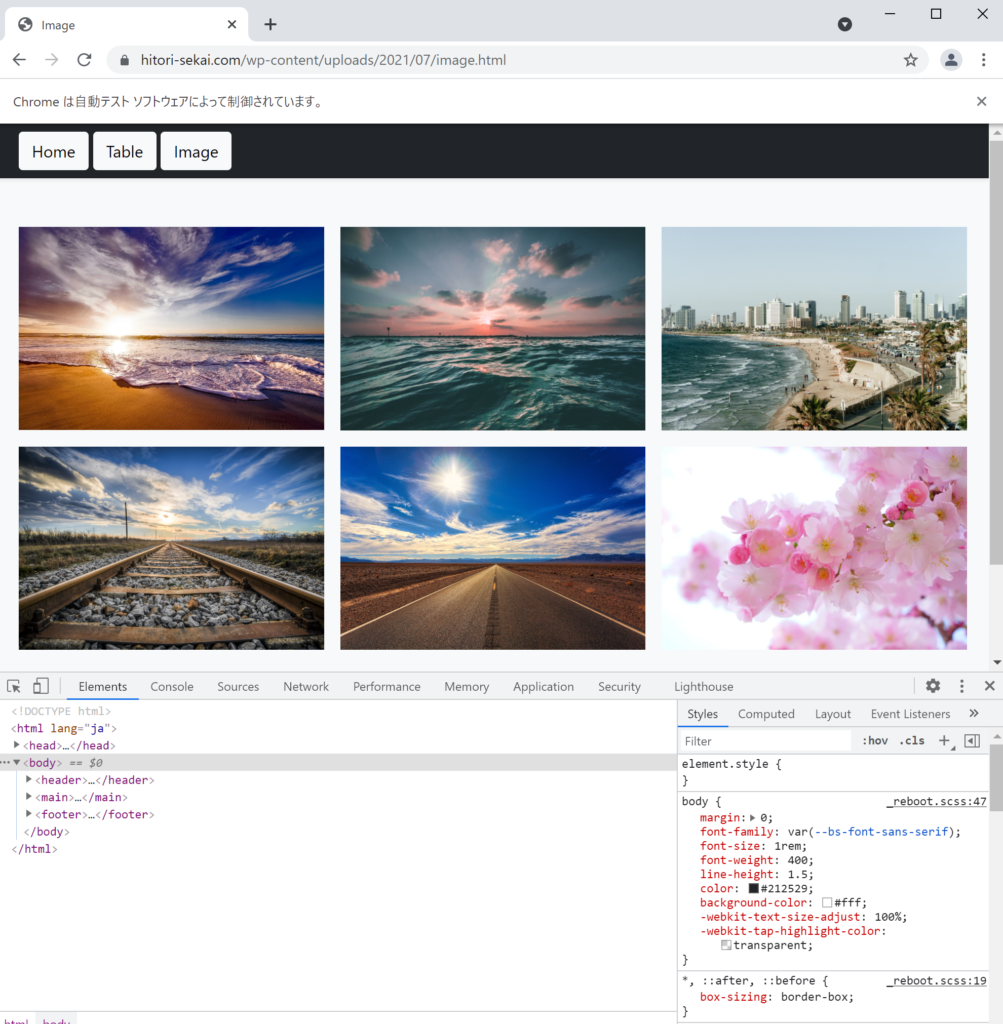
Imageボタンを押して下記のページに移動しましょう。
![]() ライブラリのインストール
ライブラリのインストール
Beautihulsoup41とrequestsを使います。
import requests
from bs4 import BeautifulSoup![]() Webサイトにアクセス~データ取得
Webサイトにアクセス~データ取得
Webサイトにアクセスします。
url = 'https://hitori-sekai.com/wp-content/uploads/2021/07/image.html'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')内容としてはrequestsでURLへアクセスを行い、BeautifulSoupを使ってHTMLの構造解析を行っております。今回は詳しいことは考えず、BeautifulSoupでスクレイピングをするには上記でアクセスすると思ってください。
soupの内容を確認するとHTML構造として得られていることが確認できます。
soup<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8"/>
<meta content="width=device-width, initial-scale=1" name="viewport"/>
<meta content="" name="description"/>
<meta content="Mark Otto, Jacob Thornton, and Bootstrap contributors" name="author"/>
<meta content="Hugo 0.79.0" name="generator"/>
<title>Image</title>
<!-- <link rel="canonical" href="https://getbootstrap.jp/docs/5.0/examples/album/"> -->
<!-- Bootstrap core CSS -->
<link crossorigin="anonymous" href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta1/dist/css/bootstrap.min.css" integrity="sha384-giJF6kkoqNQ00vy+HMDP7azOuL0xtbfIcaT9wjKHr8RbDVddVHyTfAAsrekwKmP1" rel="stylesheet"/>
<style>
.bd-placeholder-img {
font-size: 1.125rem;
text-anchor: middle;
-webkit-user-select: none;
-moz-user-select: none;
user-select: none;
}
@media (min-width: 768px) {
.bd-placeholder-img-lg {
font-size: 3.5rem;
}
}
</style>
</head>
<body>
<header>
<div class="navbar navbar-dark bg-dark shadow-sm">
<div class="container">
<div class="btn-toolbar" role="toolbar">
<div>
<button class="btn btn-light" onclick="location.href='./index.html'" type="button">Home</button>
<button class="btn btn-light" onclick="location.href='./table.html'" type="button">Table</button>
<button class="btn btn-light" onclick="location.href='./image.html'" type="button">Image</button>
</div>
</div>
</div>
</div>
</header>
<main>
<div class="album py-5 bg-light">
<div class="container">
<div class="row row-cols-1 row-cols-sm-2 row-cols-md-3 g-3">
<div class="col">
<img alt="..." class="img-fluid" height="240" src="https://cdn.pixabay.com/photo/2016/10/18/21/22/beach-1751455_1280.jpg" width="320"/>
</div>
<div class="col">
<img alt="..." class="img-fluid" height="240" src="https://images.unsplash.com/photo-1439405326854-014607f694d7?ixlib=rb-1.2.1&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1950&q=80" width="320"/>
</div>
<div class="col">
<img alt="..." class="img-fluid" height="240" src="https://images.unsplash.com/photo-1500990702037-7620ccb6a60a?ixlib=rb-1.2.1&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1950&q=80" width="320"/>
</div>
<div class="col">
<img alt="..." class="img-fluid" height="240" src="https://cdn.pixabay.com/photo/2016/07/29/19/19/railway-1555348_1280.jpg" width="320"/>
</div>
<div class="col">
<img alt="..." class="img-fluid" height="240" src="https://cdn.pixabay.com/photo/2018/02/05/23/05/road-3133502_1280.jpg" width="320"/>
</div>
<div class="col">
<img alt="..." class="img-fluid" height="240" src="https://cdn.pixabay.com/photo/2014/04/14/20/11/pink-324175_1280.jpg" width="320"/>
</div>
</div>
</div>
</div>
</main>
<footer><p class="mt-5 mb-3 text-muted">© 2021 ãããªã»ã«ã¤</p></footer>
</body>
</html>それでは、HTMLの構造から画像の場所と抽出しましょう。画像はimgタグで記載されているのでfindを使ってimgタグを抽出します。
Seleniumと同じように最初の1つだけまたは全部を抽出する方法があります。
soup.fing('img') #最初の1つだけ
soup.find_all('img') #全部imgタグのsrcという部分を取得することで画像のURLを取得できます。
soup.find('img')['src']
>>> 'https://cdn.pixabay.com/photo/2016/10/18/21/22/beach-1751455_1280.jpg'これで画像データのURLをWebブラウザから取得することができました。
![]() 取得データの出力
取得データの出力
先ほどの取得した’https://cdn.pixabay.com/photo/2016/10/18/21/22/beach-1751455_1280.jpg’のURLの画像をを可視化、保存をしてみましょう。
少しややこしいため、中身の理解は置いておいてコピペで良いと思います。
img_url = soup.find('img')['src'] #画像のURLをimg_urlに格納
#可視化・保存のためのライブラリをインポート
from PIL import Image
import io
img_binary = io.BytesIO(requests.get(img_url).content) #画像のURLから画像をバイナリーデータに変換
img = Image.open(img_binary) #バイナリーデータを画像化可視化させてみます。
img #可視化
画像を保存する。
img.save('filename.jpg') #画像を保存
いかかでだったでしょうか。Pythonを使って簡単に画像を取り出すことができました。
find_allを使って全てのimgタグを抽出した場合はf紹介した方法をfor文を使って繰り返し作業を行うことでWebブラウザ上の画像を保存することができます。
簡単にですが、下記にまとめておきます。
url = 'https://hitori-sekai.com/wp-content/uploads/2021/07/image.html'
res = requests.get(url) #Web
soup = BeautifulSoup(res.text, 'html.parser') #HTML構造解析
img_tag_list = soup.find_all('img') #imgタグをすべて取得
for i, img_tag in enumerate(img_tag_list):
img_url = img_tag['src'] #画像URL取得
img_binary = io.BytesIO(requests.get(img_url).content) #バイナリーデータ化
img = Image.open(img_binary) #画像化
img.save('{}.jpg'.format(i)) #保存まとめ

今回はPythonを使ったスクレイピングの方法を紹介しました。HTMLのタグなどの情報から簡単にテキストデータや画像データを取得するとこができます。
今回は私が作成した練習用のページになっているためHTML構造も簡単なものになっております。実際のページは複雑なものもありますが、スクレイピングを行う上では次の2つを意識しましょう。
- どの場所に
- どんなアクションを起こしたいか
紹介したスクレイピング技術を応用することでWeb上で人が行う作業を自動化をすることで作業効率をアップすることができます。また、Webスクレイピングを使うことで例えば、いくつかのWebサイトからホテルの価格などを収集してくることができます。
ヒトリセカイではプログラミングやWordPressについて情報発信をしておりますので応援よろしくお願いします。


コメント