
初級編ではAI開発ライブラリの解説と簡単な画像認識AIをTensorFlowを使って作成し、MNISTの手書き文字認識を行いました。

MNISTは簡単なデータセットであるため、3層の簡単なディープラーニングでも精度良く判別することができました。
しかし、一般物体認識(人やクルマ、犬などの一般的な物体の分類)ではもっと層の深いディープラーニングが使用されています。
これがディープラーニングと言われる所以でもあります。
今回の中級編では、一般物体認識の例として犬と猫の判別を行うことを画像認識AIにて実践したいと思います。


データセットの準備

データセットはKaggleの犬と猫の分類コンペから取得します。
Kaggle「カグル」は世界中で機械学習・データサイエンスに携わっている方が集まっているコミュニティーです。企業や政府などの組織がデータ分析やAIモデル開発の課題を提示し、賞金を出すCommpetition(コンペ)があります。
コンペには無料で参加でき、世界中のデータ分析・AI開発者のプロが作成したモデルのコードや説明が記載されておりますので、勉強を始めたばかりの人には参考になる情報がたくさんあります。

KaggleのDogs-vs-Catsより Data > Download All で全てをダウンロードします。
ダウンロードしたデータの詳細は下記になります。
dovs-vs-cas
|-- test1 (12500枚の画像)
|-- train (12500枚の犬の画像、12500枚の猫の画像)今回のデータセットはtrainフォルダからtrainデータ用として2000枚(犬1000枚、猫1000枚)、validationデータ用として400枚(犬200枚、猫200枚)をランダムに振り分け、test1フォルダの画像はtestデータ用として使用します。
Google Colaboratoryを使って行うためにGoogle Driveにデータセットをアップロードします。

これでデータセットの準備は完了です。
それでは、画像認識AIを作成して、学習させてみます。
シンプルなモデルで判別

初級編でも行ったTensorFlowを用いてシンプルな層構造の画像認識AIモデルを作成してみます。
手順は以下の通りです。
- ノートブックの作成
- ライブラリのインポート
- データセットの読み込み
- モデル構築・学習
- 学習結果
それでは1つずつ行っていきます。
![]() ノートブックの作成
ノートブックの作成
Google Colabratoryで新しいノートブックを作成し、ドライブをマウントします。
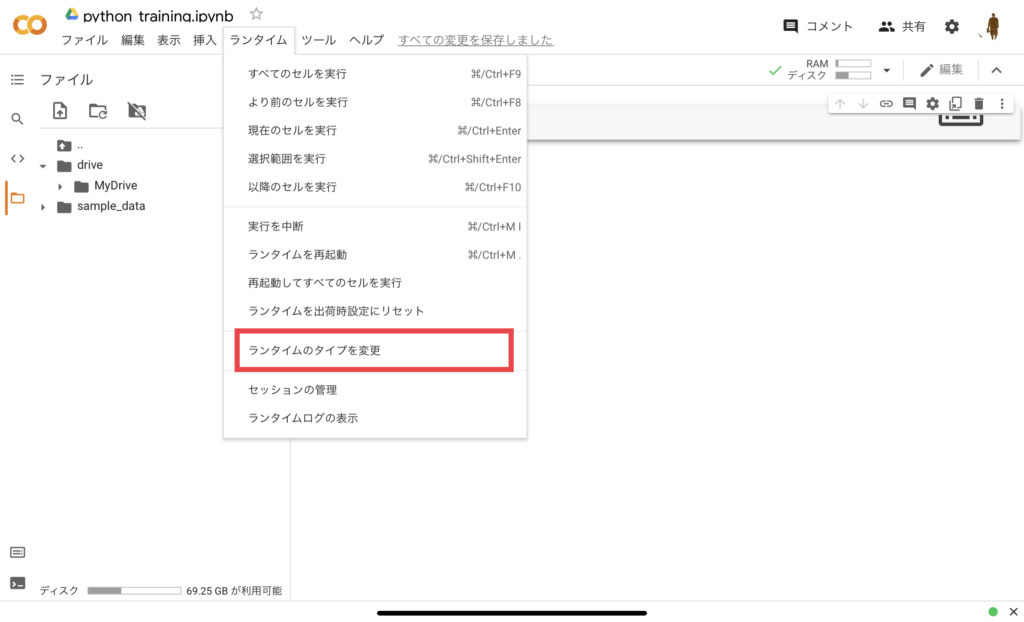
また、GPUを使うのでランタイムの設定からGPUを選択します。(ランタイム > ランタイムのタイプの変更 > GPU)
![]() ライブラリの読み込み
ライブラリの読み込み
下記のライブラリを読み込みます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Model
from tensorflow.keras import layers
from tensorflow.keras.utils import to_categorical![]() データセットの読み込み
データセットの読み込み
Google Driveにアップロードしたtrain用画像, validation用画像を読み込みます。
まずは、画像のPathを取得します。
dir_path = Path('/content/drive/MyDrive/Colab Notebooks/dog vs cat')
# train data
train_dog_pathlist = list(dir_path.glob('train/dog*'))
train_cat_pathlist = list(dir_path.glob('train/cat*'))
# validation data
val_dog_pathlist = list(dir_path.glob('validation/dog*'))
val_cat_pathlist = list(dir_path.glob('validation/cat*'))Pathが取得できていることを確認します。
len(train_dog_pathlist),len(train_cat_pathlist), len(val_dog_pathlist),len(val_cat_pathlist)
>>> (1000, 1000, 400, 400)trainy用の犬の画像を確認してみましょう。
#新規ウインドウ作成
fig = plt.figure(figsize=(14,7))
#flg全体をX*Yに分割し、plot位置に画像を配置する。
X = 2
Y = 5
#imgの表示
for i, path in enumerate(train_dog_pathlist[:10]):
ax1 = fig.add_subplot(X, Y, i+1)
im = Image.open(path)
im_list = np.asarray(im)
plt.imshow(im_list)
さまざまな犬の画像がさまざまな画像サイズであります。
この後の処理で使いやすいように犬の画像Pathと猫の画像Pathをくっつけます。
train_list = train_dog_pathlist.copy()
train_list.extend(train_cat_pathlist)
val_list = val_dog_pathlist.copy()
val_list.extend(val_cat_pathlist)
len(train_list), len(val_list)
>>> (2000, 800)関数としてPathから画像を読み込む処理を作成します。
画像サイズが統一でないため、読み込む際に$224\times224$のサイズにリサイズを行います。
def path_to_image(path_list):
image = []
for path in path_list:
im = Image.open(path)
im_resize = im.resize((224,224))
im_list = np.asarray(im_resize)
image.append(im_list)
return np.array(image)先ほど作成した関数を使ってtrainとvalidationの画像をそれぞれ読み込みます。
train = path_to_image(train_list)
val = path_to_image(val_list)
train.shape, val.shape
>>> ((2000, 224, 224, 3), (800, 224, 224, 3))また、画像データのピクセル値は0~255の値までしか取らないため、255で割ることで0~1の範囲に値を正規化します。
x_train = train/255
x_val = val/255最後にラベルデータを作成します。今回は犬と猫の2値分類問題なので犬を1、猫を0とします。
ラベルデータも前処理を行います。こちらはOne-hot vectorと呼ばれる処理を行います。
t_train = np.append(np.ones(len(train_dog_pathlist)), np.zeros(len(train_cat_pathlist)))
t_val = np.append(np.ones(len(val_dog_pathlist)), np.zeros(len(val_cat_pathlist)))
# One hot vector
t_train = to_categorical(t_train)
t_test = to_categorical(t_val)
t_train.shape,t_val.shape
>>> ((2000, 2), (800, 2))![]() モデル構築・学習
モデル構築・学習
それでは、初級編で作成したシンプルなモデル構造で今回のタスクを実践したいと思います。
tf.keras.backend.clear_session()
inputs = layers.Input(shape=x_train.shape[1:])
x = layers.Conv2D(filters=3, kernel_size=(3, 3), padding='same', activation='relu')(inputs)
x = layers.MaxPool2D(pool_size=(2, 2))(x)
x = layers.Flatten()(x)
x = layers.Dense(units=128, activation='relu')(x)
outpus = layers.Dense(units=2, activation='softmax')(x)
model = Model(inputs, outpus)
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=optimizer,
loss='binary_crossentropy',
metrics=['accuracy'])Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 224, 224, 3) 84
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 112, 112, 3) 0
_________________________________________________________________
flatten (Flatten) (None, 37632) 0
_________________________________________________________________
dense (Dense) (None, 128) 4817024
_________________________________________________________________
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 4,817,366
Trainable params: 4,817,366
Non-trainable params: 0
_________________________________________________________________batch_size =128
epochs =20
history = model.fit(x_train, t_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_val, t_val))![]() 学習結果
学習結果
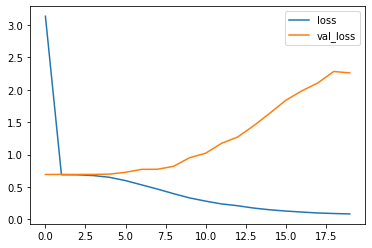
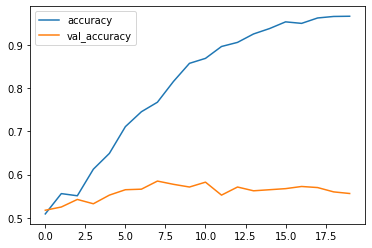
初級編では95%ほどの精度が得られたモデルでした。
今回はvalidationの精度はイマイチな結果となりました。過学習が起きていることが確認できます。
精度向上する方法としては
- モデル構造の変更
- ドロップアウトの採用
- 転移学習・ファインチューニング
といった方法があります。
モデル構造の変更やドロップアウトの採用は手探り状態になり、学習時間を要するので、今回は転移学習・ファインチューニングを使って簡単にモデル精度の向上を試みます。
転移学習

ディープラーニングの精度向上のためによく用いられる手法として転移学習やファインチューニングといったものがあります。
これらは大量のデータで学習されたモデルの出力層側のパラメータを再学習し、作成したいモデルに適合させる手法となります。
- 転移学習
:引き継いだパラメータは更新せず、追加したモデル構造のパラメータのみ学習 - ファインチューニング
:引き継いだパラメータも学習
また、高精度のディープラーニングモデルを作成するには大量の画像データが学習するのに必要となるため、少量のデータしかない場合にも転移学習を用いることで高精度な画像認識モデルを作成することができます。
今回はVGG16を使用した転移学習を実装します。
転移学習の手順は以下になります。先ほどまで行ってきたこととあまり変わらないので簡単に実装できます。
- ライブラリの読み込み
- モデルの構築・学習
- 学習結果
- 推論
それでは1つずつ行っていきます。
![]() ライブラリの読み込み
ライブラリの読み込み
VGG16に必要なライブラリを追加で読み込みます。
今回は転移学習を行うのでVGG16の全結合層の前までを取得します。また、取得したVGG16のパラメータは更新しないように設定します。
from tensorflow.keras.applications import VGG16
# 全結合層前まで取得
vgg_conv = VGG16(weights='imagenet', include_top=False, input_shape=x_train.shape[1:])
# parameteの更新しない設定
for layer in vgg_conv.layers:
layer.trainable = FalseDownloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58892288/58889256 [==============================] - 1s 0us/step
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688
_________________________________________________________________![]() モデルの構築・学習
モデルの構築・学習
分類器となる全結合層部分を作成し、読み込んだVGG16に繋げます。
# model構築
x = layers.Flatten()(vgg_conv.layers[-1].output)
x = layers.Dense(units=1024, activation='relu')(x)
x = layers.Dense(units=256, activation='relu')(x)
outpus = layers.Dense(units=2, activation='softmax')(x)
model = Model(vgg_conv.inputs, outpus)
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=optimizer,
loss='binary_crossentropy',
metrics=['accuracy'])Model: "vgg16転移学習"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 25088) 0
_________________________________________________________________
dense_5 (Dense) (None, 1024) 25691136
_________________________________________________________________
dense_6 (Dense) (None, 256) 262400
_________________________________________________________________
dense_7 (Dense) (None, 2) 514
=================================================================
Total params: 40,668,738
Trainable params: 25,954,050
Non-trainable params: 14,714,688
_________________________________________________________________batch_size =128
epochs =20
history = model.fit(x_train, t_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_val, t_val))![]() 学習結果
学習結果
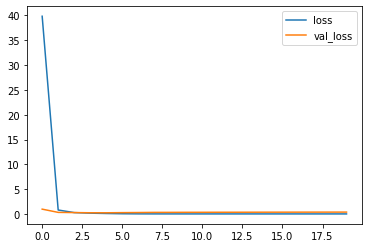

作成したモデルは誤差は低下し、精度が向上していることから学習がしっかりとできております。
先ほどとは違って、validationの精度が90%ほどあることが確認できます。
![]() 推論
推論
それでは未知のデータにおいてどれほどの精度があるか確認してみましょう。
Google Driveにアップロードしたtest用画像を使って推論を行います。
# test data
test_dog_pathlist = list(dir_path.glob('test1/*'))
# image
test = path_to_image(test_dog_pathlist[:10])
test.shape
>>>> (10, 224, 224, 3)推論の際も忘れずにデータの正規化を行いましょう。
preds = model.predict(test/255)推論結果を確認してみます。
y_preds = []
for pred in preds:
y_preds.append(np.argmax(pred))
y_preds
>>> [0, 1, 1, 1, 0, 1, 0, 1, 0, 1]推論としては結果が返ってきていることがわかります。
が、0と1だけでは何がなんだか分からないので画像と一緒に確認してみましょう。
以下のサンプルコードでは推論結果が0であれば猫、1であれば犬と画像タイトルに記すようにしました。
#新規ウインドウ作成
fig = plt.figure(figsize=(14,7))
#flg全体をX*Yに分割し、plot位置に画像を配置する。
X = 2
Y = 5
#imgの表示
for i, path in enumerate(test_dog_pathlist[:10]):
ax1 = fig.add_subplot(X, Y, i+1)
im = Image.open(path)
im_list = np.asarray(im.resize((224,224)))
if y_preds[i]==1:
plt.title('dog')
else:
plt.title('cat')
plt.imshow(im_list)
2枚の誤判定がありますが、10枚中8枚の画像を分類することができました。
VGG16は少し古いモデルのなので最新のモデルを活用することや、学習データの水増しを行うともう少し精度向上が見込めるかもしれません。
このように転移学習を用いることで簡単に高精度な判別モデルを作成することができます。
自分でモデル構造を1から考える必要もなく、お手軽に実装できるのは良いです。
Kerasの公式ドキュメントに公開されたモデルがたくさんありますので、他のモデルでの挑戦してみてください。
まとめ

今回は一般物体認識の簡単な問題として犬と猫の画像分類問題を取り上げました。
初級編ではシンプルなモデルで高精度な結果が得られましたが、データセットが複雑になるとそうはいきません。
今回の中級編では転移学習を使った複雑なモデルで学習を行い、精度向上を行いました。
VGG16は名前の通り16層のディープラーニングモデルですが、世の中には100層以上のモデルも存在します。
他にもたくさんモデルはあるので転移学習・ファインチューニングを使って精度の良いモデルを作成してみてください。


コメント